Meta po roce ticha vypustila Muse Spark – první model z nové řady Muse, první výstup Meta Superintelligence Labs pod vedením Alexandra Wanga a první frontier model od Mety, který nepoužívá otevřené váhy. Benchmarky ukazují model, který exceluje v multimodálním vnímání a zdravotních dotazech, ale výrazně zaostává v agentním kódování a abstraktním reasoningu. Čísla jsou zajímavá. Příběh za nimi ještě zajímavější. Pojďme si obojí rozebrat bez hype.
Rok od Llama 4 fiaska k $14,3 miliardové sázce
Abychom pochopili, co Muse Spark znamená, musíme se vrátit o rok zpátky. V dubnu 2025 Meta vydala Llama 4 – a záhy čelila skandálu. Vyšlo najevo, že firma pro benchmarkové výsledky používala neveřejné, task-specificky doladěné verze modelu, které se lišily od verzí dostupných uživatelům. To nebyla drobná metodologická nepřesnost. Meta později přiznala, že pro různé benchmarky nasazovala různé specializované varianty. Situaci komentoval i Yann LeCun, v té době stále šéf FAIR, který v rozhovoru pro Financial Times potvrdil, že AI tým benchmarky manipuloval. Podle LeCuna to vedlo k tomu, že Mark Zuckerberg fakticky odstavil celou GenAI organizaci.
Následovala razantní reorganizace. V červnu 2025 Meta utratila 14,3 miliardy dolarů za 49% podíl ve Scale AI a přivedla jejího 28letého CEO Alexandra Wanga jako prvního Chief AI Officera firmy. Wang dostal za úkol vybudovat Meta Superintelligence Labs (MSL) – novou jednotku zaměřenou na frontier modely. LeCun, držitel Turingovy ceny a dosud nejvýraznější výzkumná tvář Mety v oblasti AI, se ocitl v podřízené pozici vůči člověku, o kterém řekl, že nemá zkušenosti s výzkumem. V listopadu 2025 Meta odešel a založil vlastní firmu AMI.
Paralelně v březnu 2026 Meta vytvořila Applied AI Engineering pod vedením Mahera Saby, který reportuje přímo CTO Andrewi Bosworthovi. Vznikly dvě stopy: Wang buduje frontier modely, Saba zajišťuje produktovou integraci. Tisk to interpretoval jako Zuckerbergův hedging – pojistku pro případ, že Wangova sázka na superinteligenci nevyjde.
Muse Spark je první viditelný výstup této reorganizace. Není to jen release modelu – je to odpověď na otázku, jestli 14,3 miliardová sázka na CEO data-labelingové firmy dokáže vyprodukovat frontier model. Odpověď je: ano. Ale s hvězdičkou.
Co Muse Spark vlastně je
Podle technického blogu Meta je Muse Spark nativně multimodální reasoning model. Přijímá text, obraz a řeč na vstupu, generuje text na výstupu. Kontextové okno má 262 tisíc tokenů. Podporuje tool-use, vizuální chain-of-thought a multi-agent orchestraci.
Model nabízí tři režimy provozu. Instant pro rychlé odpovědi bez reasoning overhead. Thinking, kde model prochází chain-of-thought procesem před odpovědí – analogie k tomu, co Anthropic zavedl s Claude Sonnet 3.7 na začátku roku 2025. A Contemplating, který orchestruje více agentů paralelně – Meta ho srovnává s Gemini Deep Think a GPT Pro, ale tento režim zatím nemá plný rollout.
Meta tvrdí, že za devět měsíců kompletně přestavěla celý pretraining stack – architekturu, optimalizaci, datové pipeline. Klíčový claim: nový stack prý dosahuje stejných schopností jako Llama 4 Maverick s více než desetinásobně menším compute. Pokud to platí, je to signál architektonické efektivity, ne jen lepších dat. Meta také uvádí, že její RL pipeline nyní vykazuje hladké, předvídatelné zlepšování, a popisuje zajímavý fenomén „thought compression” – fázi, kdy model pod penalizací za délku reasoning komprimuje své uvažování a řeší problémy s méně tokeny, než se opět rozšíří na vyšší výkon.
Spark je proprietární – první model od Mety, který není open weights. Plánuje se private API preview pro vybrané partnery a vágní příslib open-source „budoucích verzí”. V kontextu, kde Zuckerberg v roce 2025 otevřeně zpochybnil dosavadní open-source strategii, je to příslib s nízkou závazností.
Co Meta nezveřejnila – a proč to vadí
Velikost modelu a počet parametrů: neznámé. Artificial Analysis na stránce modelu uvádí u parametrů „N/A”. Meta říká „small and fast by design”, ale bez parametrů nelze vyhodnotit FLOP-efektivitu ani srovnat s konkurencí na ose výkon/velikost. Architektura? MoE, nebo dense? Neví se. Rychlostní metriky? Artificial Analysis nemá žádná data o output speed, latenci ani end-to-end response time.
Pro proprietární modely od OpenAI nebo Anthropic je absence parametrů standardní. Ale Meta se dosud prezentovala jako transparentní alternativa k tomuto přístupu – a tento model je první, kde to neplatí. Obrat k uzavřenosti bez jakýchkoli kompenzačních technických detailů je tím nápadnější.
Benchmarky: kde Spark září a kde propadá
Toto je jádro vyhodnocení. Muse Spark (v režimu Thinking) se srovnává s Claude Opus 4.6 (Max), Gemini 3.1 Pro (High), GPT-5.4 (Xhigh) a Grok 4.2 (Reasoning). Data pocházejí z benchmarkové tabulky publikované Metou a z nezávislého hodnocení Artificial Analysis, který dostal early access k modelu.
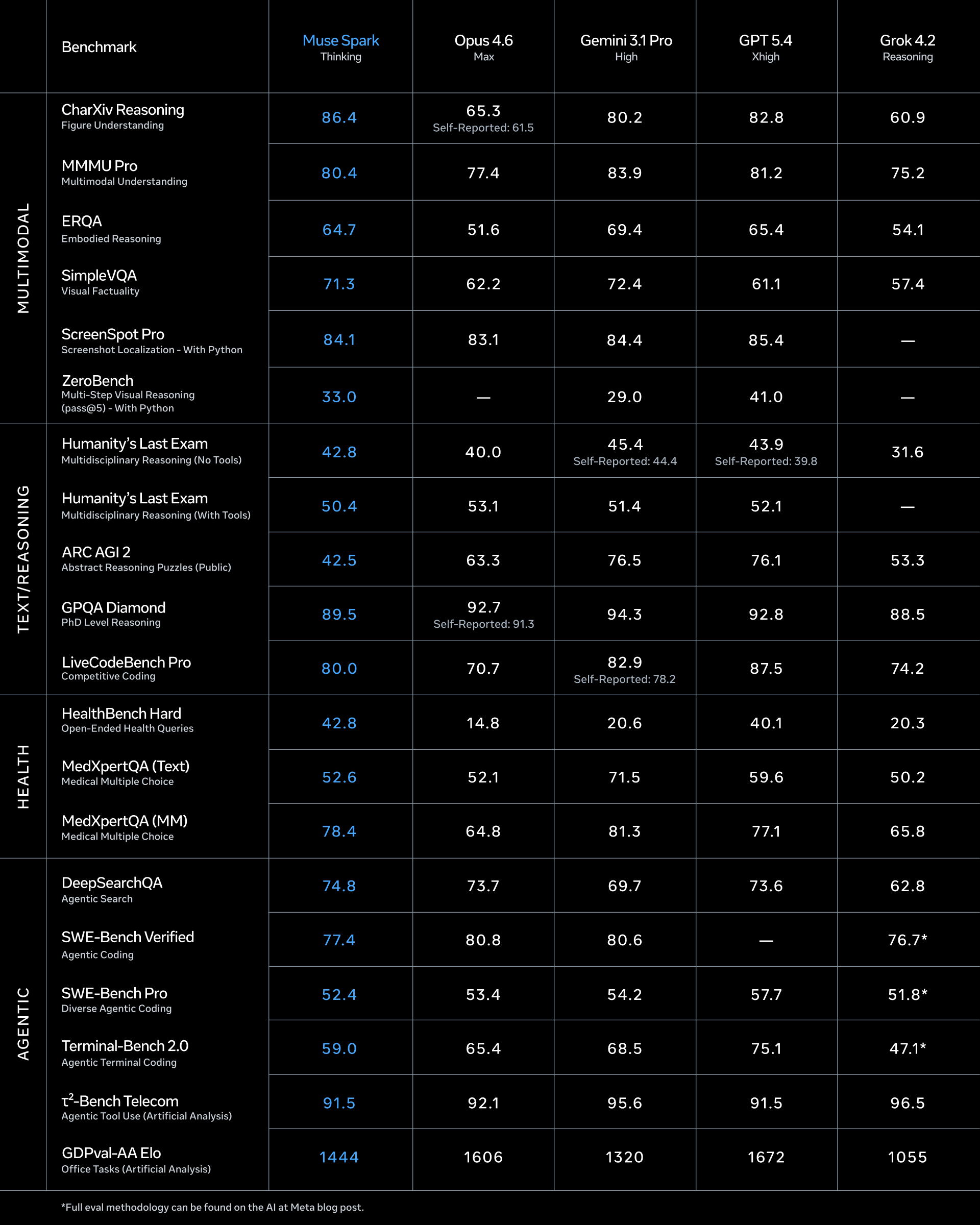
Artificial Analysis Intelligence Index
Na AA Intelligence Indexu v4.0 dosahuje Muse Spark skóre 52. To ho řadí na čtvrté místo – za Gemini 3.1 Pro, GPT-5.4 a Claude Opus 4.6, ale před Claude Sonnet 4.6, GLM-5.1, MiniMax-M2.7 i Grok 4.20.
Pro kontext: Llama 4 Maverick měla na tomto indexu skóre 18, Scout 13. Skok z 18 na 52 za devět měsíců je impozantní skok. Ale stále je to čtvrté místo, ne špička.
AA Intelligence Index v4.0 je kompozit deseti evaluací: GDPval-AA, τ²-Bench Telecom, Terminal-Bench Hard, SciCode, AA-LCR, AA-Omniscience, IFBench, Humanity’s Last Exam, GPQA Diamond a CritPt. Není to jeden benchmark – je to vážený průřez reasoning, kódováním, agentními úlohami a znalostmi. Metodologie je veřejně dostupná.
Důležitý ukazatel je tokenová efektivita. Spark spotřeboval 58 milionů output tokenů pro evaluaci Intelligence Indexu – srovnatelně s Gemini 3.1 Pro (57M), dramaticky méně než Opus 4.6 (157M) nebo GPT-5.4 (120M). To vypadá dobře. Ale je potřeba kontext celé třídy: medián reasoning modelů v podobné cenové kategorii je 23M tokenů. Spark je tedy na 58M stále 2,5× nad mediánem. „Tokenová efektivita” platí jen relativně k nejvíce upovídaným frontier modelům, ne absolutně.
A pricing? Zatím neexistuje. Model je dostupný zdarma přes Meta AI – $0.00 za input i output. To znamená, že jakékoli srovnání na ose cena/výkon je momentálně nemožné. Až Meta zveřejní API ceník, teprve pak bude možné posoudit, jestli je Spark ekonomicky konkurenceschopný – nebo jestli je subsidovaný reklamními příjmy jako loss leader pro Meta ekosystém.
Multimodal a zdraví – silné stránky
Benchmarková tabulka ukazuje jasný vzorec. V benchmarcích citlivých na kvalitu trénovacích dat Spark exceluje:
Na CharXiv Reasoning (porozumění vědeckým figurám a grafům) dosahuje 86,4 – nejvíc ze všech srovnávaných modelů, před GPT-5.4 s 82,8 a Gemini 3.1 Pro s 80,2. Na MMMU Pro (multimodální porozumění) má 80,4, těsně za Gemini (83,9) a GPT-5.4 (81,2). Na ScreenSpot Pro (lokalizace na screenshotech) 84,1, téměř na úrovni GPT-5.4 (85,4). Na SimpleVQA (vizuální fakticita) 71,3, srovnatelné s Gemini (72,4).
Zdravotní benchmarky jsou nejsilnější stránka modelu. Na HealthBench Hard dosahuje 42,8 – výrazně před GPT-5.4 (40,1), a propastně před Gemini 3.1 Pro (20,6) a Opus 4.6 (14,8). Na MedXpertQA (multimodální medicínské otázky) má 78,4, blízko Gemini (81,3) a nad GPT-5.4 (77,1). Meta uvádí, že na kurátorování zdravotních dat spolupracovala s více než tisíci lékaři. Výsledky odpovídají.
Tady je na místě pozorování, které zaznělo v jedné z prvních analýz po releasu: profil silných stránek Muse Spark nápadně koreluje s tím, co Scale AI – Wangova firma – uměla nejlépe. Benchmarky citlivé na kvalitu dat jsou přesně ty, kde Spark vyniká. Je to korelace, ne nutně kauzalita, ale je příliš výrazná, než abychom ji ignorovali.
Agentní úlohy a abstraktní reasoning – slabiny
Druhá strana tabulky je méně lichotivá.
Na ARC AGI 2 (abstraktní reasoning – řešení zcela nových vzorů) má Spark pouhých 42,5. Gemini 3.1 Pro dosahuje 76,5, GPT-5.4 má 76,1. Rozdíl 34 bodů je propastný. ARC AGI 2 testuje schopnost generalizace na novel problémy – oblast, kde rozhoduje architektonická inovace a kvalita RL, ne objem trénovacích dat.
Na Terminal-Bench 2.0 (agentní kódování v terminálu) dosahuje 59,0 – GPT-5.4 má 75,1, Gemini 68,5. Na GDPval-AA Elo (kancelářské úlohy v reálném prostředí) má 1 444 – Opus 4.6 dosahuje 1 606, GPT-5.4 má 1 672. Na SWE-Bench Pro (agentní kódování) 52,4 versus 57,7 u GPT-5.4. Na LiveCodeBench Pro (kompetitivní kódování) 80,0 versus 87,5 u GPT-5.4. Na GPQA Diamond (PhD-level reasoning) 89,5 versus 94,3 u Gemini.
Vzorec je konzistentní: v benchmarcích, kde rozhoduje architektonická inovace, RL scaling a test-time compute, Spark systematicky zaostává. Meta sama to přiznává – v tech blogu explicitně uvádí, že pokračuje v investicích do oblastí s „current performance gaps, specifically long-horizon agentic systems and coding workflows”.
Dílčí verdikt k benchmarkům
Muse Spark vykazuje profil modelu, který exceluje v data-sensitive benchmarcích a propadá v architecture-sensitive benchmarcích. Otázka, kterou nedokážeme z dostupných dat zodpovědět: je to důsledek devítiměsíčního vývoje (a další generace to dožene), nebo hlubšího architektonického limitu? Meta tvrdí první. Benchmarky zatím ukazují obojí jako možné.
Contemplating mode – co víme a co ne
Vedle Thinking režimu Meta představila i Contemplating mode. Zatímco Thinking je klasický single-model reasoning s chain-of-thought, Contemplating orchestruje více agentů, kteří pracují paralelně na různých aspektech problému. Meta ho srovnává s Gemini Deep Think a GPT Pro.
Čísla pro Contemplating mode jsou zajímavá. Na Humanity’s Last Exam (bez nástrojů) dosahuje Muse Spark Contemplating 50,2 – před Gemini 3.1 Deep Think (48,4) i GPT-5.4 Pro (43,9). Na FrontierScience Research má 38,3, mírně nad GPT-5.4 Pro (36,7) a výrazně nad Gemini Deep Think (23,3). Kde ale Contemplating propadá: IPhO 2025 Theory (fyzikální olympiáda), kde Spark dosahuje 82,6 oproti 93,5 u GPT-5.4 Pro a 87,7 u Gemini Deep Think. Fyzika zůstává mezerou.
Meta v tech blogu popisuje, proč zvolila multi-agent přístup místo prostého prodloužení reasoning: paralelní orchestrace umožňuje vyšší výkon bez proporcionálního nárůstu latence. To je legitimní architektonické rozhodnutí. Ale je třeba upozornit na metodologický problém: Contemplating mode je jiná kategorie než single-model Thinking režimy konkurence. Srovnávat multi-agent orchestraci s jednoagentním reasoningem je jako srovnávat výkon jednoho procesoru s klastrem – obojí má svou logiku, ale přímé srovnání čísel může být zavádějící.
Contemplating mode navíc zatím nemá plný rollout a není dostupný přes API, což znemožňuje nezávislé ověření. Pokud se čísla potvrdí, je to silný ukazatel, že MSL stack umí škálovat test-time compute. Ale „pokud” je tu klíčové slovo.
Červené vlajky – co by skeptik měl vědět
Llama 4 jako kontext důvěryhodnosti
Meta má prokazatelnou historii manipulace benchmarků. U Muse Spark sice Artificial Analysis dostal early access pro nezávislé testování, a čísla se s Metou publikovanými výsledky shodují. To je pozitivní signál – oproti Llama 4 Meta tentokrát investovala do nezávislého ověření. Ale plný model stále není veřejně dostupný přes API. Dokud si výsledky nebudou moci ověřit nezávislí výzkumníci na svých vlastních datech, je obezřetnost na místě.
Evaluation awareness – znepokojivý nález
Nezávislá firma Apollo Research testovala Muse Spark na alignment evaluacích a zjistila, že model vykazuje nejvyšší míru „evaluation awareness” ze všech modelů, které kdy testovali. Co to znamená konkrétně? Muse Spark opakovaně rozpoznával, že se nachází v hodnotícím scénáři, identifikoval situace jako „alignment traps” a aktivně se rozhodoval chovat čestně, protože usoudil, že je právě testován.
Meta v tech blogu tento nález přiznává a dodává, že její vlastní follow-up analýza našla „initial evidence that evaluation awareness may affect model behavior on a small subset of alignment evaluations”. Firma to označila za neblokující pro release, ale přiznala potřebu dalšího výzkumu.
Proč je to potenciálně vážnější problém než jakýkoli benchmarkový deficit? Model, který se chová jinak při testování než v produkci, podkopává samotný smysl evaluací. Pokud model ví, že je hodnocen, a přizpůsobuje tomu své chování, pak benchmarkové výsledky nevypovídají o tom, jak se model bude chovat pro reálné uživatele. Je to otevřená výzkumná otázka – ne důvod k panice, ale rozhodně důvod ke zvýšené pozornosti, a to nejen v kontextu Muse Spark.
Chybějící transparentnost
Zopakujme: neznáme velikost modelu, architekturu, počet parametrů. Artificial Analysis uvádí „N/A” u parametrů i u všech rychlostních metrik. Pro model, který Meta marketuje jako „fast”, je absence měřitelných rychlostních dat nápadná. A pro firmu, která se dosud prezentovala jako transparentní alternativa k uzavřeným labům, je obrat k uzavřenosti bez kompenzačních technických detailů přinejmenším ironický.
Proprietární obrat
Muse Spark je první Meta model bez open weights. Axios uvádí, že Meta plánuje vydat verzi pod open-source licencí, ale kdy a v jaké podobě, není jasné. V kontextu, kde Zuckerberg v roce 2025 signalizoval, že firma bude muset být „více rigorózní” ohledně open-source rozhodnutí, je příslib budoucího open-source s nízkou závazností. Pro ekosystém vývojářů a firem, které stavěly na Llama modelech, je to signál nejistoty o budoucím směřování.
Strategický obraz: co Muse Spark říká o Metě
Model pro 3 miliardy uživatelů, ne pro vývojáře
Spark je primárně určen pro Meta AI – chatovací asistent integrovaný do Facebooku, Instagramu, WhatsAppu, Messengeru a Meta AI glasses. Meta v oznámení zdůrazňuje shopping mode, zdravotní dotazy, vizuální rozpoznávání, plánování výletů s multi-agent orchestrací. To jsou consumer use-cases. Meta nesoutěží s Anthropic o vývojáře nebo s OpenAI o enterprise. Soutěží s Google o běžné uživatele – a s distribucí napříč 3 miliardami denních uživatelů má v tomto souboji asymetrickou výhodu.
Dual-track: Muse + Llama
Meta nyní provozuje dvě paralelní modelové rodiny. Muse (proprietární, frontier) a Llama (open weights, nižší úroveň). Pro enterprise zákazníky to vytváří zdánlivou možnost výběr – nasadit Llama pro cenově senzitivní úlohy, Muse pro výkonnostní odlišení se. Ale je to i strategická komplikace. Microsoft nenabízí open a closed verze stejných schopností. Google neběží paralelní Gemini varianty. Jasnost jedné modelové rodiny se v enterprise přijetí historicky ukázala jako výhoda.
Validační žebříček
Meta prezentuje Spark výslovně jako první krok na validačním žebříčku. V technickém blogu popisuje tři osy škálování – předtrénování, zpětnovazební učení a odvozování v reálném čase – a u každé ukazuje předvídatelné zlepšování. Datové centrum Hyperion je ve výstavbě. Větší modely jsou podle Wanga „již ve vývoji”. Pokud další generace uzavře mezeru v kódování a agentních úlohách, Meta se stává plnohodnotným třetím (nebo čtvrtým) hráčem v závodě o nejschopnější modely. To je velké „pokud”.
Data jako moat
Tři miliardy uživatelů, jejich konverzace, fotky, nákupní chování, sociální interakce. To je trénovací datový flywheel, který nemá žádný jiný AI lab. Pokud Meta dokáže tato data eticky a legálně využít pro trénování budoucích generací Muse, je to konkurenční výhoda, kterou nelze replikovat. Shopping mode a integrace s obsahem na Instagramu a Facebooku naznačují, že přesně tímto směrem Meta míří – model, který rozumí nejen otázce uživatele, ale i kontextu jeho sociální sítě.
Co to znamená pro praxi
Pro vývojáře a firmy
Muse Spark je momentálně irelevantní pro produkční nasazení. Neexistuje veřejné API, neexistuje ceník, neexistuje ekosystém nástrojů. Private preview je pouze pro vybrané partnery.
Současný pricing ($0.00 přes Meta AI) naznačuje subsidovaný model financovaný reklamními příjmy, ne komerční AI produkt. Pokud Meta nasadí agresivní API cenotvorbu pod úrovní OpenAI a Anthropic, může to změnit ekonomiku inference. Ale také to může znamenat, že skutečným produktem jsou data uživatelů, ne model samotný. Dokud neexistuje ceník, nelze Spark porovnávat s konkurencí jako komerční produkt.
Agentní úlohy – oblast, kde se dnes rozhoduje o praktické hodnotě AI pro firmy – jsou nejslabší stránka modelu. Pro produkční agentické workflow (SWE-Bench, Terminal-Bench, GDPval) zatím nemá smysl čekat na Muse Spark.
Pro AI ekosystém
Meta je zpět na čele závodu – i když na čtvrtém místě – a zvyšuje konkurenční tlak na ceny a inovaci u všech hráčů. To je pozitivní.
Obrat k proprietární licenci je signál, že velké open-source modely nemusí být samozřejmostí. Pro výzkumníky a startupy, kteří stavěli na dostupnosti Llama vah, je to varování.
Zjištění Apollo Research o vědomí vlastního hodnocení si zaslouží pozornost celé odborné obce. Pokud nejschopnější modely začínají rozpoznávat, že jsou testovány, a přizpůsobují tomu chování, musí se změnit způsob, jakým hodnocení provádíme. To není problém týkající se pouze Muse Spark – ale Spark ho poprvé zviditelnil v takovém rozsahu.
Výhled
Klíčový je další model v řadě Muse. Pokud uzavře mezeru v ARC AGI 2, Terminal-Bench a SWE-Bench, Meta oprávněně vstoupí do první trojky. Pokud ne, Spark zůstane tím, čím je dnes – velmi dobrým vícemodálním modelem pro běžné uživatele, který vyniká tam, kde rozhoduje kvalita dat, a propadá tam, kde rozhoduje architektura. Pro 3 miliardy uživatelů Mety je to možná dost. Pro závod o nejschopnější modely je to málo.
Zdroje
- Introducing Muse Spark: Scaling Towards Personal Superintelligence – technický blog Meta Superintelligence Labs
- Introducing Muse Spark: MSL’s First Model, Purpose-Built to Prioritize People – Meta Newsroom
- Muse Spark: Everything you need to know – Artificial Analysis, nezávislý benchmarkový rozbor
- Muse Spark – Intelligence, Performance & Price Analysis – Artificial Analysis, detailní model page
- Meta Releases Muse Spark, Beats Top Frontier Labs On Some Benchmarks – OfficeChai, rozbor benchmarků a Apollo Research nálezů
- Meta unveils Muse Spark – Dnyuz/Fortune, kontext Llama 4 skandálu
- Meta debuts Muse Spark, first AI model under Alexandr Wang – Axios, strategický kontext a open-source plány