Oficiální komunikace se soustředí na benchmarky, lepší zpracování obrazu a nová nastavení míry uvažování modelu. Technický čtenář ale dostane přesnější obraz, když vydání zařadí do kontextu tří paralelních pohybů, které Anthropic v posledních měsících provedl - a které se v PR materiálu logicky neobjevují. Pojďme si tedy projít zákulisí miliardového boje o AI.
Co skutečně přibylo a za jakou cenu
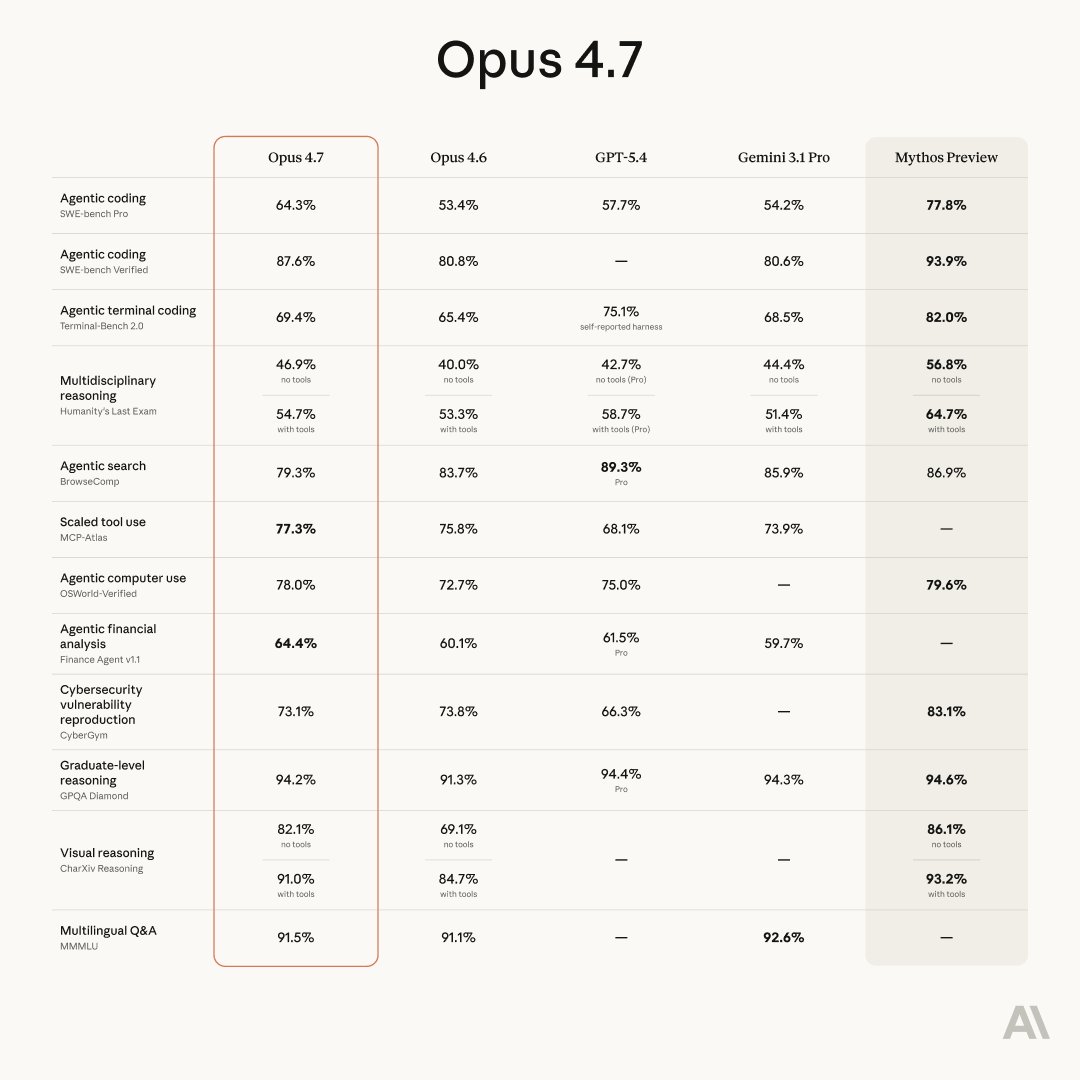
Formálně je přírůstek oproti Opus 4.6, který jsem srovnával s GPT-5.3-Codex, měřitelný a na několika benchmarcích výrazný. Na SWE-bench Pro skočil model z 53,4 % na 64,3 %, na SWE-bench Verified z 80,8 % na 87,6 %. Největší skok je ve vision - na CharXiv Reasoning bez nástrojů ze 69,1 % na 82,1 %, s nástroji ze 84,7 % na 91,0 %. Model nově přijímá obrázky o straně až 2 576 pixelů, tedy více než trojnásobek oproti předchozí generaci. To má reálný dopad na computer-use agenty čtoucí hustě obsazené screenshoty, na extrakci dat z technických diagramů a na workflow v patentových rešerších. Tam, kde jsou velké obrázky potřeba.
Zlepšení v agentním kódování potvrzují i partneři v testech na předběžných verzích. XBOW uvádí 98,5 % na svém benchmarku vizuální přesnosti oproti 54,5 % u Opus 4.6 - tedy skokové zlepšení právě v těch scénářích, kde Opus 4.6 systematicky selhával. Notion Agent hlásí 14% nárůst úspěšnosti úloh při nižší spotřebě tokenů a třetinovém počtu chyb v tool calls. CodeRabbit udává zlepšení recallu u code review o více než 10 % při zachované preciznosti. Tyto metriky jsou ovšem dodány partnery s motivací dodat pozitivní citát. Napříč výpověďmi konzistentně vystupují tři vlastnosti: lepší dodržování instrukcí, méně wrapper funkcí a generického ochranného kódu, důkladnější sebeověření před dokončením úlohy.
Vyšší spotřeba tokenů
Za tyto změny k lepšímu se ale platí. Model používá nový tokenizer, který stejný vstup mapuje na 1,0 až 1,35 násobek tokenů v závislosti na typu obsahu. Nový tokenizer, nutný pro lepší vision kapacitu a strukturované výstupy, ale zvyšující spotřebu tokenů o 0-35 % podle typu obsahu. Model při vyšších effort úrovních myslí déle, zejména na pozdějších turnech v agentních sessions - to Anthropic přiznává sám. A v Claude Code je nově defaultní effort level xhigh, tedy o stupeň výš, než byl březnový default u 4.6. Kombinace těchto tří změn znamená, že reálná tokenová spotřeba na dokončenou úlohu u Opus 4.7 je systémově vyšší než u 4.6 - bez ohledu na to, že katalogová cena 5/25 dolarů za milion tokenů se nezměnila. Anthropic ukazuje graf “skóre vs. tokeny” na interním benchmarku, kde vychází příznivě, ale to je jedna úloha v řízeném prostředí.
Konkrétní data tokenizéru jsem pro vás ověřil pro jednotlivé jazyky. Naměřené hodnoty pro stejný odstavec (~380 znaků) ve čtyřech evropských jazycích: vycházejí takto:
Počty tokenů při převodu odstavce textu
| Jazyk | G3 Flash | G3.1 Pro | GPT-5.1 | GPT-5.4 | Claude 4.6† | Opus 4.7 | vs 4.6 |
|---|---|---|---|---|---|---|---|
| English | 65 | 65 | 72 | 72 | 85 | 135 | +58,8 % |
| Czech | 114 | 115 | 128 | 128 | 143 | 189 | +32,2 % |
| Slovak | 125 | 125 | 142 | 142 | 158 | 210 | +32,9 % |
| German | 90 | 90 | 94 | 94 | 138 | 186 | +34,8 % |
† Claude Haiku 4.5, Sonnet 4.6 a Opus 4.6 sdílejí identický tokenizér.
Tučně = nejnižší počet tokenů.
Regrese Opusu 4.7 je pro angličtinu dramaticky vyšší (+59 %) než pro češtinu nebo slovenštinu (+33 %) — nový tokenizér je méně efektivní právě tam, kde staré verze byly nejsilnější.
Z tabulky, kterou Anthropic zveřejnil, stojí za pozornost také to, co v ní není. GPT-5.4 má u SWE-bench Verified pomlčku. U CharXiv Reasoning proti GPT-5.4 a Gemini je pomlčka. U agentní finanční analýzy proti Mythosu pomlčka. Jsou to strategická vynechání - Anthropic testuje benchmarky na takových kombinacích, kde jeho model vede, a tiše opomíjí zbytek.
Mythos Preview: skutečně nejlepší model, který nikdy nedostaneme
V tabulce Anthropicu svítí sloupec, kterému nikdo nevěnoval pozornost. Mythos Preview má 77,8 % na SWE-bench Pro (Opus 4.7 má 64,3 %), 93,9 % na SWE-bench Verified (Opus 4.7 má 87,6 %), 82,0 % na Terminal-Bench 2.0 (Opus 4.7 má 69,4 %). Rozdíl mezi Opus 4.7 a Mythos je větší než rozdíl mezi Opus 4.6 a Opus 4.7. To znamená, že to, co dnes Anthropic nabízí veřejnosti, není jeho nejlepší model, a není to ani blízko jeho nejlepšího modelu.
Mythos Preview byl odhalen koncem března 2026 náhodou - misconfigurací CMS, která nechala veřejně dostupný draft blog post. Oficiálně Anthropic model představil 7. dubna v rámci Project Glasswing, iniciativy s dvanácti technologickými a finančními korporacemi (AWS, Apple, Google, Microsoft, Nvidia, Cisco, JPMorgan, Palo Alto Networks a dalšími). Model za několik týdnů testování identifikoval tisíce zero-day zranitelností v každém velkém operačním systému a prohlížeči. Nejstarší objevená chyba byla v OpenBSD - 27 let neznámá.
Anthropic zdůvodňuje omezenou dostupnost bezpečnostními riziky. Mythos umí podle firmy samostatně řetězit zranitelnosti a autonomně vyvíjet exploity, což Opus 4.6 nezvládal. To je přesvědčivý technický argument. Je ale také obchodním argumentem: Mythos bude pro Glasswing partnery dostupný za 25/125 dolarů za milion tokenů - tedy pětinásobek ceny Opus 4.7. Obchodní model Anthropicu se tak štěpí na dva proudy: B2B kanál s nejlepším modelem pro kritickou infrastrukturu za prémiovou cenu a mainstream API s uhlazenou verzí pro zbytek trhu.
V oznámení Opus 4.7 je zakopaná věta, která tenhle model definuje přesněji než všechny benchmarky: “Opus 4.7 is the first such model: its cyber capabilities are not as advanced as those of Mythos Preview (indeed, during its training we experimented with efforts to differentially reduce these capabilities).” Jinými slovy - Opus 4.7 je zkušební pole pro filtry, které teprve v budoucnu mají umožnit širší nasazení Mythos-class modelů. Není to frontier model, je to testovací prostředí pro safeguards.
GLM-5.1 a strukturální tlak, který Anthropic nezmiňuje
Druhý sloupec, který v oficiální tabulce chybí, patří čínskému GLM-5.1 od Z.ai (dřívější Zhipu AI, první veřejně obchodovaná firma v oboru foundation modelů po lednovém IPO v Hongkongu). Když GLM-5.1 vyšel 27. března 2026 (psali jsme), dosáhl na SWE-bench Pro skóre 58,4 % - tedy v té době #1 globálně, nad GPT-5.4 (57,7 %), Claude Opus 4.6 (57,3 %) a Gemini 3.1 Pro (54,2 %). Nezávislá verifikace přes Code Arena (1530 Elo, třetí místo) tohle číslo potvrdila.
To, co GLM-5.1 dělá pro trh, ale není nejlepší skóre. Je to kombinace tří parametrů, která strukturálně mění kalkulaci:
- Open-weights pod licencí MIT, váhy volně na Hugging Face
- Trénovaný kompletně na čipech Huawei Ascend 910B, bez jediné Nvidie (Z.ai je na nepřátelském US Entity Listu od ledna 2025)
- Cena API 1,00/3,20 dolaru za milion tokenů - tedy pětinová až osminová oproti Opus
Opus 4.7 teď GLM-5.1 na SWE-bench Pro překonává (64,3 % vs. 58,4 %), ale iterační cyklus Z.ai je rychlejší. GLM-5 vyšel 11. února, GLM-5-Turbo 15. března, GLM-5.1 API 27. března, open-weights 7. dubna - tedy čtyři významné verze za dva měsíce. Další iterace GLM-5 velmi pravděpodobně vyjde dříve než Opus 4.8. A open-weights model za pětinu ceny, který v agentním kódování zaostává za uzavřeným komerčním modelem o několik bodů, je pro většinu reálných pracovních nasazení ekonomicky racionální volbou.
K tomu přichází Cursor 3 (vydaný 2. dubna 2026, psal jsem zde) s modelem Composer 2 za 0,50/2,50 dolaru za milion tokenů - tedy desetina ceny Opus 4.7. Composer 2 je podle VentureBeat fine-tune čínského open-source modelu Kimi K2.5 a na SWE-bench Multilingual má 73,7 %. Pro vývojáře sedící v Cursoru je Opus 4.7 jedna z možností, ne default. A když Cursor řeší auto-routing mezi modely strukturálně na úrovni IDE, otázka “kdy stojí za to zaplatit nejdražší model” má najednou úplně jinou odpověď.
Tohle Anthropic v oznámení nezmiňuje, a pochopitelně. Ale jde o reálný konkurenční tlak, který definuje kontext, v němž Opus 4.7 vzniká.
Kauza AMD: co se dělo v Anthropicu předchozí dva měsíce
Dne 2. dubna 2026 otevřela Stella Laurenzo, Senior Director AI compiler týmu v AMD (funkce odpovídá vedoucímu týmu či divize, není to ředitelka AI v AMD, jak se někde mylně uvádí), issue #42796 v repozitáři anthropics/claude-code. Nešlo o běžnou stížnost. Laurenzo ve svém týmu provedla analýzu 6 852 reálných sessions z ledna až března, obsahujících 234 760 tool calls a 17 871 thinking bloků. Zjištění:
- Medián délky reasoningu klesl z ~2 200 znaků na ~600 znaků (pokles o 67-73 %)
- Poměr čtení souborů před editací klesl z 6,6 na 2,0 (model edituje “naslepo”)
- “Stop-hook” violations (předčasné ukončení, dotazy typu “mám pokračovat?”) narostly z nuly před 8. březnem na 173 případů za následujících 17 dní
- Sebekontradikce se ztrojnásobily
Závěr: “Claude has regressed to the point it cannot be trusted to perform complex engineering.” AMD tým přešel k jinému poskytovateli (Laurenzo odmítla specifikovat kvůli NDA).
Anthropic reagoval dvoufázově. Boris Cherny, vedoucí Claude Code, nejdřív v pinned odpovědi na GitHubu tvrdil, že regrese souvisí s přechodem defaultního effort levelu z high na medium 3. března, a navrhl /effort high. Laurenzo odpověděla, že tým už dávno používá effort=max a nepomáhá to. Cherny posunul narativ na Hacker News: přiznal, že adaptive thinking (zavedené 9. února) na některých turnech alokuje nulový reasoning budget, což přesně vysvětluje halucinace typu smyšlené git SHA, neexistující apt balíčky a API verze, které nikdy nevyšly. Doporučil workaround CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING=1. Issue byl uzavřen jako “completed” - ne vyřešen, ale uzavřen.
Laurenzoová analýza není bez slabin. Její hypotéza o “GPU-load-sensitive thinking allocation” (nejhorší výsledky v americké pracovní době, zlepšení v noci) je interpretace, kterou Anthropic oficiálně odmítl. Nárůst API requestů 80× a nákladů 122× je částečně artefaktem toho, že AMD tým záměrně škáloval z 1-3 na 5-10 souběžných agentů - to smíchává degradaci s úmyslným rozšířením. Ale jádro zůstává: Cherny sám přiznal zero-reasoning bug v adaptive thinking, změny proběhly bez release notes a bez notifikace uživatelů, a je to pátý podobný incident za posledních osm měsíců.
Kauza AMD není jediný doklad, ale je nejkvalitněji dokumentovaná. BridgeBench mezi 12. a 14. dubnem zveřejnil data, podle kterých Opus 4.6 propadl z druhé na jedenáctou pozici v benchmarku halucinací. Paul Calcraft (externí AI výzkumník) tu interpretaci rozebral: původní skóre bylo ze šesti úloh, nové ze třiceti, na překrývajících se šesti se výkon posunul z 87,6 % na 85,4 %. Re-test ze 14. dubna s 30 úlohami pak dal Opus 4.6 účet 72,2 % - tedy ve střední části leaderboardu, kde první tři místa patří Grok 4.20 Reasoning (90,0 %), GPT-5.4 (83,3 %) a Qwen 3.6 Plus (75,2 %). Na halucinace a kalibrace sebedůvěry modelu (confidence calibration) Claude prostě není špička, i když to jeho marketing rád tak tvrdí.
Ekonomická reforma, kterou Anthropic provedl mezitím
Zatímco komunita řešila “nerfování” modelu, Anthropic zároveň tiše měnil základní obchodní model pro enterprise zákazníky. To je zásadně důležitý kontext, ve kterém Opus 4.7 vzniká.
Do začátku roku 2026 Anthropic nabízel enterprise (tedy velkým firemním uživatelům) paušál 40-200 dolarů za uživatele měsíčně včetně kvóty tokenů a slevy na API 10-15 %. Od prvního čtvrtletí 2026 přechází na nový model: “seat” poplatek klesá na 20 dolarů měsíčně, ale přestává obsahovat spotřebu tokenů. API slevy jsou zrušeny. Firmy musí předem závazně objednat odhadnutou měsíční spotřebu tokenů - a platit ji bez ohledu na využití. Překročení závazku se fakturuje standardními API sazbami bez slevy. Riziko přecenění nebo podcenění spotřeby je plně na zákazníkovi.
Načasování není náhodné. Anthropic v dubnu 2026 oznámil roční tempo tržeb přes 30 miliard dolarů - nárůst z 1 miliardy před 16 měsíci. Claude Code sám generuje 2,5 miliardy dolarů ARR a aktivní báze se od ledna zdvojnásobila. API dostupnost za posledních 90 dní je 98,95 % - tedy pod cloudovým standardem 99,99 % a dostatečně nízká, aby David Hsu, zakladatel firmy Retool, přešel na OpenAI a veřejně to zdůvodnil. To není “optimalizace” - to je reálný kapacitní problém, s jakým se Anthropic potýká. Sám jsem už v jednom případě narazil na školení na to, že nebylo možné Claude Code na workshopu používat, protože neběžel.
Konverzační chat spotřebuje typicky 1 000-5 000 tokenů na výměnu. Claude Code v agentním módu spotřebuje desetinásobek i víc. Tým tří agentů spotřebuje přibližně 7× více tokenů než jednoagentní session, protože každý agent udržuje vlastní kontext a běží jako samostatná instance modelu. Komunita zdokumentovala případy, kdy oprava chyby za 0,50 dolaru vyústila v účet 30 dolarů po 47 iteracích smyčky agenta. Jeden vývojář dokumentoval 10 miliard tokenů za osm měsíců - odhadovaná cena na API by přesáhla 15 000 dolarů, skutečná platba přes plán Max byla přibližně 800 dolarů. Anthropic tak dotoval poměr 19:1 u power userů provozujících agentní workflow. To je reálná změna na trhu: agentní kódování, v němž několik agentů hledá řešení problému ze všech stran, dává lepší výsledky, ale stojí prostě víc.
Tenhle finanční model byl dlouhodobě neudržitelný, což je asi nejlogičtější pozorování celého počátku roku 2026. Paušál 200 dolarů měsíčně s neomezenou spotřebou fundamentálně nefunguje, když agentní model za jednu session spálí tisíce dolarů v API ekvivalentu. Paralelní kroky OpenAI (přechod Codexu z paušálu na tokeny, nový 100dolarový tier), GitHubu (zpřísnění Copilot limitů od 10. dubna) a Windsurfu (náhrada kreditů denními kvótami v březnu) nejsou náhoda - celý segment provádí stejnou korekci z téhož důvodu.
Anthropic ale tuhle korekci podle některých kritiků provedl technicky zvlášť cynicky: zkrácení doby platnosti prompt cache v Claude Code z hodiny na pět minut (začátek března) tiše zvýšilo spotřebu kvót u dlouhých sessions, protože cache přestala pokrývat celý pracovní blok. Ano, podle mého (a podle oficiálního výkladu) to byla spíše technická chyba či rekonfigurace, která se zřetězila a promítla tak, že někteří uživatelé se rychle dostávali na dno svého limitu kvóty.
Tři fáze jednoho tržního manévru
Když se všechny tyto informace zařadí do časové osy, vystoupí obrazec, který Anthropic v žádném oficiálním materiálu nepřizná, ale který je z veřejných dat rekonstruovatelný:
Fáze 1 (únor-březen 2026): Tiché snížení kvality, ať již řízené nebo neúmyslné. Adaptive thinking s občasným zero-reasoning bugem (9. února). Změněný effort z high na medium (3. března), byť to bylo oznámeno. Zkrácení prompt cache z hodiny na pět minut (začátek března), byť to zřejmě byla chyba. Efekt: průměrný uživatel dostává levnější odpovědi, Anthropic šetří výpočetní výkon, ale nároční uživatelé vnímají zhoršení služby.
Fáze 2 (první čtvrtletí 2026): Přeúčtování. Přechod enterprise zákazníků na nový model - paušál dolů, povinné nákupy balíku tokenů, API slevy zrušeny, riziko přecenění na zákazníkovi. Efekt: Anthropic přestává dotovat power usery a inkasuje tržby odpovídající skutečné spotřebě. Tato reforma probíhá v tichosti, zatímco komunita řeší degradaci kvality modelu.
Fáze 3 (16. dubna 2026): Vydání Opus 4.7. Xhigh jako nový default v Claude Code (ale nic jako to, co bylo high v lednu). Task budgets v beta. Auto mode pro Max. Nový tokenizer s 1,0-1,35× vyšší tokenovou spotřebou. Model, který si Anthropic rámuje jako “při vyšších úrovních effortu uvažuje déle, zejména v pozdějších fázích agentních úloh”. Efekt: kvalita se vrací, ale spotřeba tokenů je systémově vyšší než u 4.6. A na novém cenovém modelu to jde přímo do nákladů.
Task budgets jsou obzvlášť zajímavá fíčurka, kterou marketingově Anthropic prodává jako výhodu pro vývojáře. Ve skutečnosti je to tvrdý limit, který přesouvá odpovědnost za kontrolu nákladů na uživatele. V lednu 2026 ti Anthropic dotoval přešlapy. V dubnu 2026 ti dává nástroj, abys je nedělal - ale účet za ně platíš sám.
Co z toho plyne pro technického uživatele
Opus 4.7 je dobrý model. Benchmarky jsou reálné, upgrade zpracování obrazu je skokové, self-verification v agentních sessions podle partnerů měřitelně funguje. Ale žádná z těchto vlastností neopravňuje tvrzení, které si Anthropic nechá říct svými partnery - že jde o “nejlepší model na trhu”. Na trhu je Mythos za prémiovou cenu pro vybrané organizace. A v konkurenční perspektivě je tu GLM-5.1 za pětinu ceny a Composer 2 za desetinu ceny, a obojí pro 80-90 % reálných úloh stačí.
Pro plánování vývojářského workflow z toho plynou konkrétní důsledky:
- TCO kalkulace musí zahrnovat tokenovou spotřebu, ne jen předplatné. Kdo v roce 2025 nasazoval Claude bez sledování tokenů, v roce 2026 to sledovat začne nebo dostane nečekaný účet. Konkrétně pro agentní workflow s vícero souběžnými agenty jde o řády, ne o procenta.
- Xhigh default v Claude Code znamená vyšší účty bez úpravy promptů. Pokud pracuješ na rutinním kódu,
/effort mediumnebo/effort lowmají svůj smysl - a pro rutinní úlohy se vyplatí zvážit Fast Mode. Rozhodně nespouštěj Claude Code na default s očekáváním nákladů podle staré ceny. - Konkrétní optimalizační taktiky: pravidelné
/clearpři přechodu mezi nesouvisejícími úkoly, downgrade na Sonnet pro rutinu (Opus pro složitou architekturní práci, Sonnet pro implementaci), delegování verbose výstupů (testy, logy, dokumentace) na subagenty se souhrnem vracejícím se do hlavní session, tvrdé limity iterací u vlastních agentních pipeline. - Strategická diverzifikace: GLM-5.1 a Composer 2 nejsou exotické alternativy. Jsou to racionální volby pro konkrétní typy workloadů. Pro open-source projekty, self-hosting nebo pro data-sensitive kontext (kde export do USA je problém) je GLM-5.1 s váhami na Hugging Face principiálně lepší odpověď než jakýkoli proprietární model.
- Očekávej další incident “nerfování” za 3-4 měsíce. Pokud Anthropic drží linii, kde nedostatek výpočetní kapacity je jeho reálný problém a Mythos čeká na bezpečnostní pojistky, další tichá optimalizace přijde. Základní sázka Anthropicu - embargo nejlepšího modelu z bezpečnostních důvodů plus postupná ekonomická korekce mainstreamu - funguje jen do doby, dokud Z.ai a další hráči nemají ekvivalent Mythosu. Časový rozdíl se podle mne aktuálně počítá v měsících, ne v letech…
Závěr
Claude Opus 4.7 není technologická událost. Je to ekonomický manévr, a jeho technologický obsah je tomu manévru přesně přizpůsoben. Anthropic má tři modelové úrovně, které odrážejí ne technologickou hierarchii, ale segmentaci platby: Mythos za prémiovou cenu pro vybrané partnery, Opus 4.7 jako mainstream za standardní cenu (která je ale vyšší než se zdá kvůli tokenizeru, xhigh defaultu a novému enterprise modelu), a sluhu Sonnet pro rutinu, kterou si Opus nemůže dovolit dělat. Haiku bych nepočítal, sorry.
Pro technického uživatele je dnes klíčová ne otázka “který model je nejlepší”, ale “který model dává nejlepší výsledek za jakou cenu na který workload, a jak se budou ceny a kvality vyvíjet v dalších třech měsících”. Anthropic na tu otázku ve svém PR materiálu neodpovídá. Článek, který si zachovává alespoň minimální kritickou distanci, by měl.